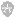实战core dump
2014-07-09 10:27:47 来源:我爱运维网 评论:0 点击:
C++开发难免会遇到core dump的问题,但是我们有gdb和valgrind两个强大的工具可以帮到我们。这里就不重复工具介绍,网上多的是。本文主要讲...

C++开发难免会遇到core dump的问题,但是我们有gdb和valgrind两个强大的工具可以帮到我们。这里就不重复工具介绍,网上多的是。
本文主要讲述实战中遇到的问题和解决方法:
1. 堆栈乱,gdb无能为力。
这明显不是正常堆栈。也就是说:堆栈乱了。多次尝试按gdb提示的错误点修复,发现治标不治本。gdb已经无力了,valgrind隆重登场。
2. valgrind调试遇到c语言strcat类似函数的问题
众所周知,strcat等c语言函数有安全问题。但是老代码中还是使用了这些函数,它们通过代码逻辑本身保证安全。但是valgrind还是会提示错误,这时只能逐一替换成相应安全函数,比如strncat.避免太多错误信息。
3. valgrind glibc 静态链接问题。
如果你的程序的makefile是用 -static链接的,恭喜你中奖了,valgrind调试中会看到大量莫名其妙的错误。
看如下说明:
Does valgrind just not work with -static?
It does. The problem is not in Valgrind,it's in glibc, which is not Valgrind clean. The glibc developers refused to fix these problems.
解决方法就是去掉makefile中的-static
3、mem leak的一般性处理方法。
问题描述: 程序一晚上内存占了30G,正常不可能占如此多的内存。(事后原因分 析:持续使用的对象,比如管理上下文的对象,持续往里面写,却因为某些原因没 有删除,导致内存持续不断增长。
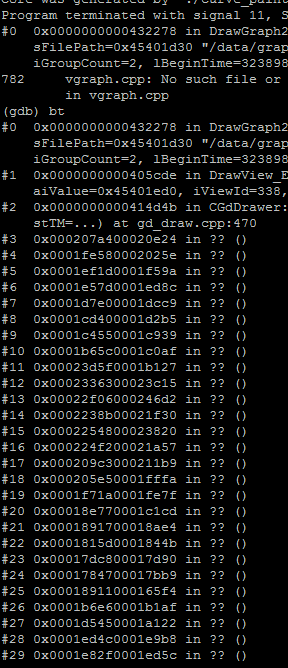
解决方法:我还是按照上一篇文章中的方法用valgrind去监控进程是否有mem_leak,很显 然,这个次的问题不能算是典型的mem leak,因为实际上这个管理上下文的对象还 是可达的(只不过它在不断膨胀)。这个时候是检测不到的。但是valgrind功能不 是这么简单。我们来看看c++进程的profile:
使用命令: valgrind --tool=massif ./xxmain
过一段时间,使用命令:ms_print massif.out.13364
肉眼检查谁的内存在持续增长。
如上图(第一列为内存占用比例,最后一列是bug出现的代码行)
总结: 对于Reachable MEM Leak可以使用上述方法解决。
4、cpu过高问题的一般性解决方案。
写了一个程序单台server部署了5个进程。发现cpu间歇100%,整机负载超过15.虽然只有4个cpu,但也不至于如此费CPU。怎么搞?
先说下shushengwu提供的方案一:
1. gdb -p processid
2. thread apply all bt
每隔几秒钟执行一次2,看看所有线程中有哪个函数出现的概率最大,可能就是它在占cpu了。
方案二: valgrind的callgrind工具
1. valgrind --tool=callgrind ./forward_storm_proc2 ../conf/forward_storm_proc2_1.ini 然后等几分钟,等待函数调用数积累起来
2. 命令行方式查看 callgrind.out.pid.
callgrind_annotate --tree=caller callgrind.out.pid >caller.log 注意参数caller表示打印调用方(*表示谁被调用,<表示各个调用方)。比如我这里找出来调用量最大的函数是memcpy,然后找到调用它的函数。
或者采用图形化方案,有windows版本的工具,绿色版,很方便。
请看下图:
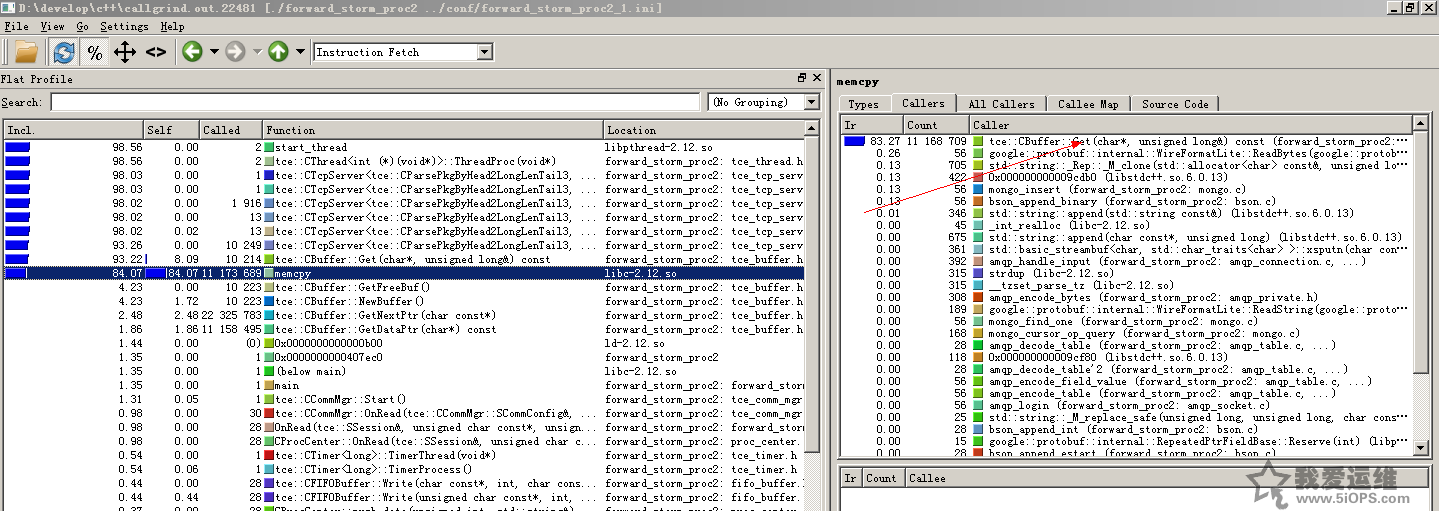
左边调用栈显示了最大调用的函数是memcpy,右边显示它的调用者占比最大的是程序中的Get方法。问题就定位到了是单次buf申请太小,导致频繁memcpy。
总结:熟练工建议使用方案一,已经验证过是比较准确的。方案二好处图形可视化。
上一篇:strace使用详解及应用案例
下一篇:活用redis经验及数据类型
分享到:
 收藏
收藏
收藏
评论排行
- ·Windows(Win7)下用Xming...(92)
- ·使用jmx client监控activemq(20)
- ·Hive查询OOM分析(14)
- ·复杂网络架构导致的诡异...(8)
- ·使用 OpenStack 实现云...(7)
- ·影响Java EE性能的十大问题(6)
- ·云计算平台管理的三大利...(6)
- ·Mysql数据库复制延时分析(5)
- ·OpenStack Nova开发与测...(4)
- ·LTPP一键安装包1.2 发布(4)
- ·Linux下系统或服务排障的...(4)
- ·PHP发布5.4.4 和 5.3.1...(4)
- ·RSYSLOG搭建集中日志管理服务(4)
- ·转换程序源码的编码格式[...(3)
- ·Linux 的木马程式 Wirenet 出现(3)
- ·Nginx 发布1.2.1稳定版...(3)
- ·zend framework文件读取漏洞分析(3)
- ·Percona Playback 0.3 development release(3)
- ·运维业务与CMDB集成关系一例(3)
- ·应该知道的Linux技巧(3)
频道总排行