你造吗-必须知道的16个Linux服务器监控命令
2014-05-25 14:08:31 来源:我爱运维网 评论:0 点击:
在使用Linux服务器的过程中,有16个命令可以帮助你全面了解你的服务器的运行状况。如果你能够很熟练地掌握这些命令,就离成为一名专业的Lin...

在不同的Linux发行版中,会有不同的GUI程序可以显示各种系统信息,比如SUSE Linux发行版中,就有非常棒的图形化的配置和管理工具YaST,KDE桌面环境里的KDE System Guard也很不错。
然而,对于一名Linux系统管理员来说,除非迫不得已,否则不会在Linux服务器上去运行这样的GUI程序,主要还是因为GUI会占用很多的系统资源。所以呢,使用GUI工具一般都是做简单的排查,如果你真的想知道系统里真正发生了什么,那么请关掉你的GUI,快点进入Linux命令行的世界吧。
如果希望追求最佳性能,那么Linux服务器应该运行在runlevel 3级别,也就是支持网络和多用户功能,但不支持GUI功能。如果你真的需要GUI,那么可以在命令行输入startx进入GUI。
如果你的Linux系统默认就是进入GUI,你可以调一调配置,让他默认进入runlevel 3。具体方法就是:
1 打开一个终端,su到root账号 2 用你喜欢的编辑器(vi/emacs/...)打开/etc/inittab文件 3 查找initdefault关键字,将“id:5:initdefault:”修改为“id:3:initdefault:”
如果系统中根本就没有/etc/inittab文件的话,也没关系,直接创建这个文件,并添加新的一行“id:3”。这样的话,你再重启服务器,便会默认进入命令行状态。当然,如果你只想在临时进入命令行状态,那么直接在终端中输入“init 3”就好了。
至此,我们的命令行准备好了,下面就可以开始通过强大的命令来查看“到底服务器里发生了什么”:
[01 - iostat ] [02/03 - meminfo/free ] [04 - mpstat ] [05 - netstat ] [06 - nmon ] [07 - pmap ] [08/09 - ps/pstree ] [10 - sar ] [11 - strace ] [12 - tcpdump ] [13 - top ] [14 - uptime ] [15 - vmstat ] [16 - wireshark ]
[01 - iostat]
iostat命令显示的是你的存储系统的细节状态。你通常可以用这个命令去检测你的存储设备是否工作正常,
完全可以在用户抱怨服务器慢之前,通过这个命令发现系统IO方面的问题。
如下可以看到iostat既可以显示CPU使用情况,也可以看到每个磁盘的IO情况。
[shell]# iostat 1
Linux 2.6.32-220.4.1.el6.i686 (roclinux) 2012年12月22日 _i686_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.55 0.00 0.03 0.02 0.00 99.40
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sdb 0.41 2.61 5.76 2558664 5653872
sda 0.24 0.80 4.12 784650 4038344[/shell]
[02/03 - meminfo/free]
meminfo提供了很详细的内存使用状况。可以直接用cat命令查看:
cat /proc/meminfo
当然meminfo里包含了太多细节,你可以直接使用free命令来查看有关内存的综述。
[shell]# free -m
total used free shared buffers cached
Mem: 1513 1429 83 0 343 836
-/+ buffers/cache: 249 1263
Swap: 0 0 0[/shell]
[04 - mpstat]
mpstat用在多处理器的服务器上,用来显示每一个CPU的状态。
另外,mpstat也会显示所有处理器的平均状况。
你可以设置显示每个服务器的CPU统计信息,或者每个处理的CPU统计信息。
[shell]# mpstat -P ALL
Linux 2.6.32-220.4.1.el6.i686 (roclinux) 2012年12月22日 _i686_ (4 CPU)
17时46分35秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
17时46分35秒 all 0.55 0.00 0.03 0.02 0.00 0.00 0.00 0.00 99.40
17时46分35秒 0 0.84 0.00 0.04 0.03 0.00 0.01 0.00 0.00 99.08
17时46分35秒 1 0.51 0.00 0.03 0.02 0.00 0.00 0.00 0.00 99.44
17时46分35秒 2 0.45 0.00 0.02 0.01 0.00 0.00 0.00 0.00 99.51
17时46分35秒 3 0.40 0.00 0.02 0.01 0.00 0.00 0.00 0.00 99.56
# mpstat -P 0
Linux 2.6.32-220.4.1.el6.i686 (roclinux) 2012年12月22日 _i686_ (4 CPU)
17时46分39秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
17时46分39秒 0 0.84 0.00 0.04 0.03 0.00 0.01 0.00 0.00 99.08[/shell]
其中各个域的含义简述如下:
1 CPU:处理器编号,如果为all,则此行表示的是所有处理器的统计平均值 2 %usr:用户态的CPU利用率 3 %nice:具有调度优先级的用户态CPU利用率 4 %sys:内核态CPU利用率(此值不包括响应硬件中断和软件中断的时间) 5 %iowait:处理IO请求导致CPU处于IDLE状态的时间百分比 6 %irq:CPU响应硬件中断的时间比率 7 %soft:CPU响应软件中断的时间比率 8 %steal:当虚拟机监控器在服务于其他虚拟处理器时,虚拟CPU的被动等待时间比率 9 %guest:运行一个虚拟处理器所消耗的CPU时间比率
[05 - netstat]
netstat命令,是Linux系统管理员几乎每天都会用到的命令(它已经逐步在被ss命令取代),他可以显示很多有关网络方面的信息,例如socket使用情况、路由情况、网卡情况、协议情况、网络流量统计等等。
一些常用的netstat选项包括:
-a : 显示所有socke信息 -r : 显示路由信息 -i : 显示网卡借口统计 -s : 显示网络协议统计
[06 - nmon]
nmon是Nigel’s Monitor的缩写,它是一个很知名的监视Linux系统性能的工具。
nmon可以查看到处理器利用率、内存使用率、运行队列信息、磁盘IO统计、网络IO统计、换页统计等。
你可以通过一个基于curses的类GUI界面来查看到上述信息。
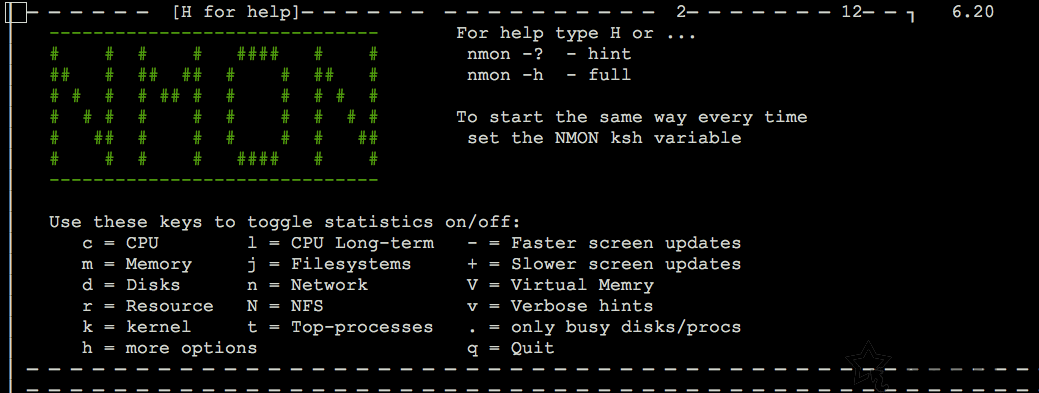
nmon监控工具
[07 - pmap]
pmap命令可以显示进程占用的内存量。
你可以通过pmap找到那个占用内存量最多的进程。
如下就是nignx主进程所占用的内存情况:
[shell]
# pmap 2395|head -n 10
2395: nginx: master process ./sbin/nginx
00110000 240K r-x- /lib/libgssapi_krb5.so.2.2
0014c000 4K —- /lib/libgssapi_krb5.so.2.2
0014d000 4K r—- /lib/libgssapi_krb5.so.2.2
0014e000 4K rw— /lib/libgssapi_krb5.so.2.2
0014f000 12K r-x- /lib/libcom_err.so.2.1
00152000 4K r—- /lib/libcom_err.so.2.1
00153000 4K rw— /lib/libcom_err.so.2.1
00154000 48K r-x- /lib/libnss_files-2.12.so
00160000 4K r—- /lib/libnss_files-2.12.so
…
b78e4000 20K rw— [ anon ]
b78f3000 4K rw-s- /dev/zero (deleted)
b78f4000 4K rw— [ anon ]
bfeaa000 84K rw— [ stack ]
total 7280K
[/shell]
[08/09 - ps/pstree]
ps和pstree在Linux系统里是一对好兄弟,它们都是用来列出处于运行状态的进程的列表的。
ps告诉我们每个进程使用的内存量以及所消耗的CPU时间。
pstree则会告诉我们进程间的父子关系,如下便是mysql的一些父子关系信息:
# pstree -p 1829
mysqld_safe(1829)───mysqld(2307)─┬─{mysqld}(2309)
├─{mysqld}(2310)
├─{mysqld}(2311)
├─{mysqld}(2312)
├─{mysqld}(2313)
├─{mysqld}(2314)
├─{mysqld}(2315)
├─{mysqld}(2316)
├─{mysqld}(2317)
├─{mysqld}(2318)
├─{mysqld}(2320)
├─{mysqld}(2321)
├─{mysqld}(2322)
├─{mysqld}(2323)
├─{mysqld}(2325)
├─{mysqld}(2544)
├─{mysqld}(2548)
├─{mysqld}(7912)
├─{mysqld}(7914)
├─{mysqld}(7916)
├─{mysqld}(24689)
├─{mysqld}(27329)
└─{mysqld}(27331)
|
[10 - sar]
sar命令堪称系统监控工具里的瑞士军刀。
sar命令实际上是由三个程序组成的,即sar(用于显示数据)、sa1(用于采集数据)和sa2(用于存储数据)。
sar可以涵盖到CPU利用率信息、内存换页信息、网络IO传输信息、进程创建行为和存储设备行为。
sar和nmon的最大区别在于,sar更适用于长期的系统监控,而nmon则更适用于快速查看信息。
如果希望更详细的学习sar命令,可以阅读[Linux下常用工具sar的简介] 及【善于sar工具来分析系统问题】。
[11 - strace]
starce经常被用来作为追查程序问题的工具,但他的功能远非如此。
它可以解析和记录进程的系统调用行为,这使得strace成为了一个非常有用的诊断、调查和纠错工具。
举例来说,你可以适用strace来追查到一个程序在启动之初所需加载的配置文件信息。
当然,strace也有它自身的缺陷,那就是strace会严重拖慢调查对象(某个进程)的性能和运行速度。
顺便推荐一篇非常好的strace的文章:[strace使用详解及应用案例 ]
另外,如果你使用MAC,strace的替代品是truss。
[12 - tcpdump]
tcpdump是一个简单的、好用的网络监控工具。它的网络协议分析能力使得它能够看清网络中到底发生了什么,如果你希望更细节的调查的话,可以考虑适用功能更为强大的wireshark工具。
tcpdump的系列教程“在这里”,实用案例看【利用tcpdump抓包分析CGI被刷案例一则】。
[13 - top]
top命令可以显示系统中的进程信息。默认情况下,top会按照CPU使用率从高到低来显示系统中的进程,并且每5秒刷新一次排行榜。
当然,你也可以让top按照PID、进程寿命、CPU耗时、内存消耗等维度对进程进行排序。(我经常使用的是P和M快捷键,分别是按CPU利用率排序、按内存使用量排序)
通过top命令,你可以很快的发现那些失去控制或不符合预期的进程。
[14 - uptime]
通过uptime命令可以查看系统已经运行了多久,可以统计当前处于登陆状态的用户数量,还可以显示当前服务器的负载情况。
[shell]
# uptime
18:35:17 up 11 days, 9:30, 1 user, load average: 0.00, 0.00, 0.00
[/shell]
[15 - vmstat]
大多数情况下,你可以使用vmstat命令去查看系统的虚拟内存情况,因为Linux通常会通过虚拟内存来获得更好的存储性能。
如果你的程序占用了大量了内存,那么系统会进行内存页换出的动作,以便把程序从内存中移动到系统SWAP空间中,也就是硬盘中。
如果系统的内存页的换入换出动作频度超过一个临界值,那么这种状态被叫做“Thrashing”。当系统处于thrashing状态时,性能会急剧下降。
vmstat命令便可以帮助人们及时发现此类问题,找出那个拖慢系统的元凶。
[shell]
# vmstat 1
procs ———-memory———- —swap- —-io—- -system- —-cpu—-
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 57484 356864 861332 0 0 0 1 7 3 1 0 99 0 0
0 0 0 57468 356864 861360 0 0 0 0 336 145 6 1 94 0 0
0 0 0 57468 356864 861360 0 0 0 0 43 51 0 0 100 0 0
0 0 0 57468 356864 861360 0 0 0 16 51 62 0 0 100 0 0
[/shell]
[16 - wireshark]
Wireshark的前身叫做Ethereal,我们可以认为wireshark是tcpdump命令的大师兄,因为wireshark会更为专业,也具有更高级的协议分析和统计能力。
Wireshark同时具有GUI界面和shell借口。
如果你是一位资深的网络管理员,那么你一定使用过ethereal。而如果你正在使用wireshark/ethereal,那么我推荐你阅读Chris Sander的一本非常好的书《Practical Packet Analysis》。
上一篇:调整centos系统时间
下一篇:tcp_tw_recycle和tcp_timestamps导致connect失败问题
分享到:
 收藏
收藏
收藏
评论排行
- ·Windows(Win7)下用Xming...(92)
- ·使用jmx client监控activemq(20)
- ·Hive查询OOM分析(14)
- ·复杂网络架构导致的诡异...(8)
- ·使用 OpenStack 实现云...(7)
- ·影响Java EE性能的十大问题(6)
- ·云计算平台管理的三大利...(6)
- ·Mysql数据库复制延时分析(5)
- ·OpenStack Nova开发与测...(4)
- ·LTPP一键安装包1.2 发布(4)
- ·Linux下系统或服务排障的...(4)
- ·PHP发布5.4.4 和 5.3.1...(4)
- ·RSYSLOG搭建集中日志管理服务(4)
- ·转换程序源码的编码格式[...(3)
- ·Linux 的木马程式 Wirenet 出现(3)
- ·Nginx 发布1.2.1稳定版...(3)
- ·zend framework文件读取漏洞分析(3)
- ·Percona Playback 0.3 development release(3)
- ·运维业务与CMDB集成关系一例(3)
- ·应该知道的Linux技巧(3)
频道总排行